|
I’m a Principal Research Scientist & Research Lead at NVIDIA, working on multimodal LLMs. I’ve led projects across the VILA model family, focusing on post-training, agent capabilities, and multimodal reasoning, with full-stack optimization for NVIDIA hardware. I joined NVIDIA Research as part of the Learning and Perception Research Team, after completing my Ph.D. at Princeton University. I was named one of Forbes Top 60 Elite Chinese in North America and received 36Kr Global Outstanding Chinese Power 100 Award. Google Scholar / CV / Linkedin |

|
|
For intern/full-timer to join NVIDIA's multimodal efforts, please send a CV to dannyy [at] nvidia [dot] com. 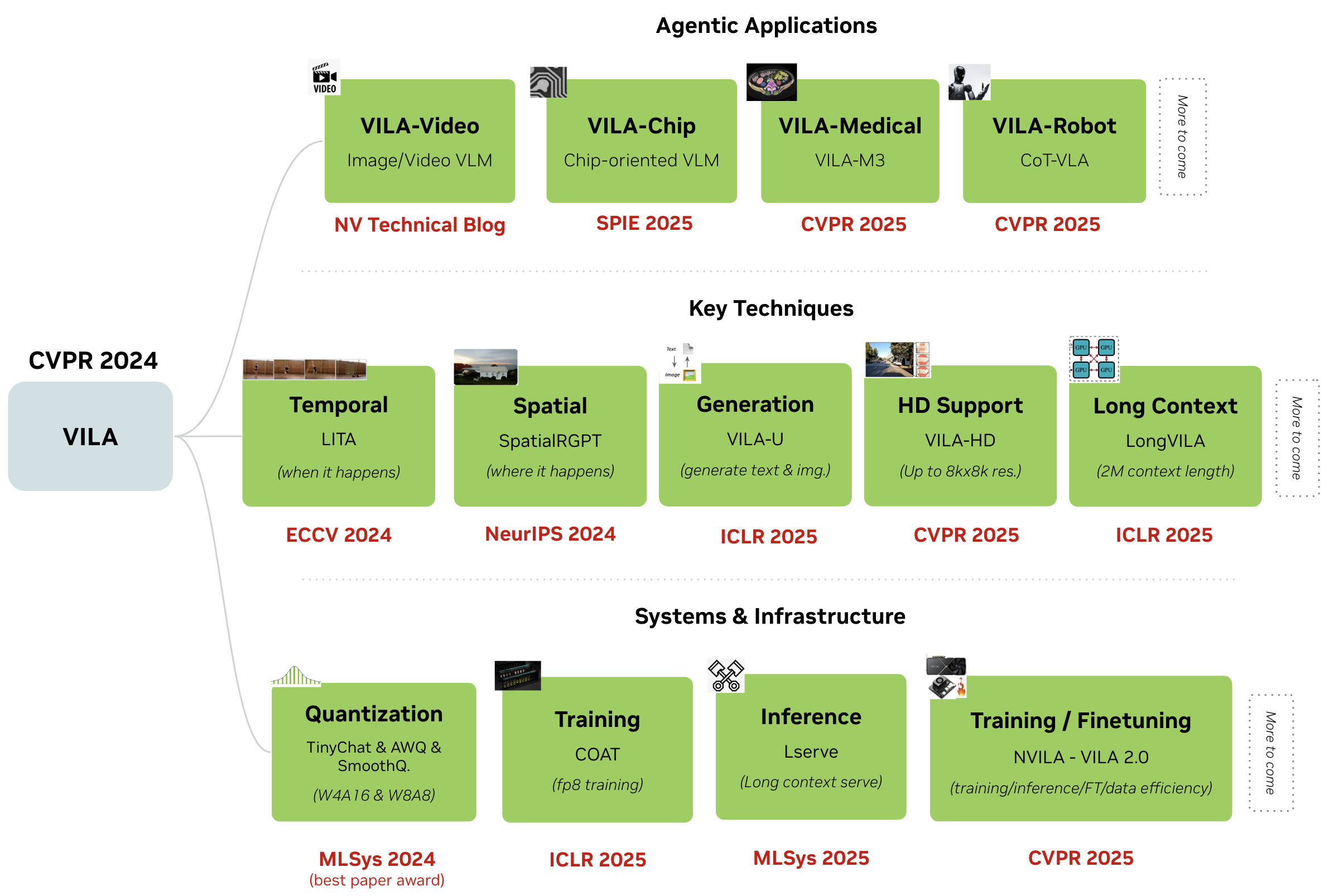
|
|
[2025 Sep] Four papers accepted at NeurIPS 2025 on multimodal reasoning, benchmark, vision encoder and training data selection. [2025 Jun] We just released VILA-based VLAs for robots for navigation (NaVILA) and manipulation (CoT-VLA and EgoVLA). [2025 Feb] Four papers accepted at CVPR 2025 on LLM and VLM, of which two as Highlight (VILA Medical Agent, and VILA-HD 4Kx4K Agent, NVILA/VILA2.0 base, and RADIO v2 vision encoder). [2025 Feb] We will host the Efficient Computer Vision workshop and GPU-based DL Acceleration tutorial at CVPR 2025. See you in Nashville. [2025 Jan] Four papers accepted at ICLR 2025 on LLM and VLM, of which one as Spotlight. [2024 Sep] Two papers accepted at NeurIPS 2024 on LLM and VLM, of which one as Spotlight. [2024 May] Three papers accepted at ICML 2024 on efficient and secure LLMs, of which two as Oral (top 1.5%). [2024 Apr] We will host the Efficient Foundation Model workshop at ECCV 2024. See you in Milan. [2024 Mar] FedBPT won the Best Paper Award at AAAI symposium. Congrats to Jingwei! [2024 Feb] Two papers accepted at CVPR 2024 on VLMs. |
|
Full list here. * equal contribution. ^ interns. ‡ equal advisory. |
|
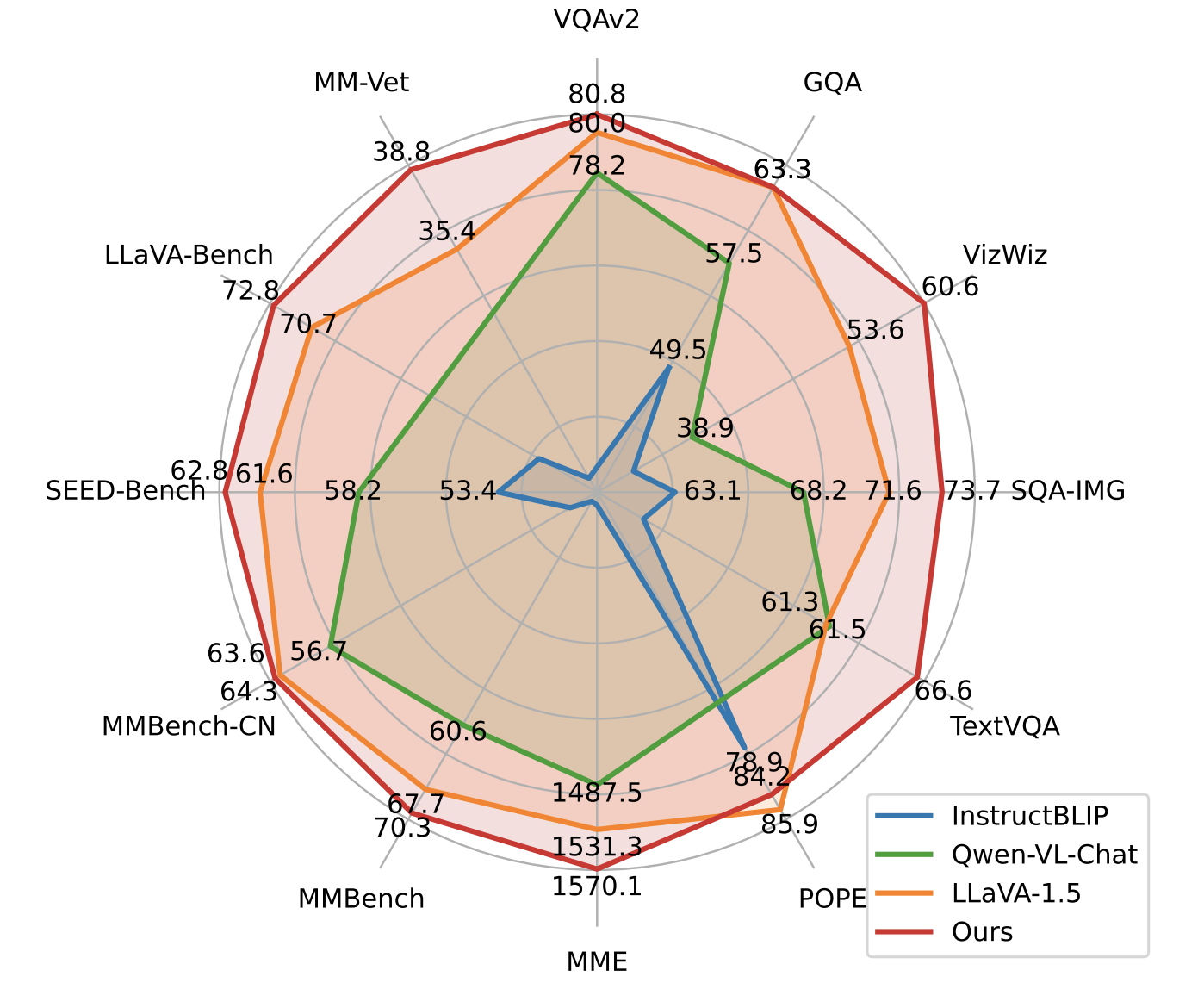
Ji Lin*^, Hongxu Yin*, Wei Ping, Yao Lu, Pavlo Molchanov, Andrew Tao, Huizi Mao, Jan Kautz, Mohammad Shoeybi, Song Han CVPR, 2024 arXiv / code / NVIDIA Technical Blog / NVIDIA Jetson Tutorial With an enhanced pre-training recipe we build VILA, a Visual Language model family that consistently outperforms the state-of-the-art models, e.g., LLaVA-1.5, across main benchmarks without bells and whistles. |
|
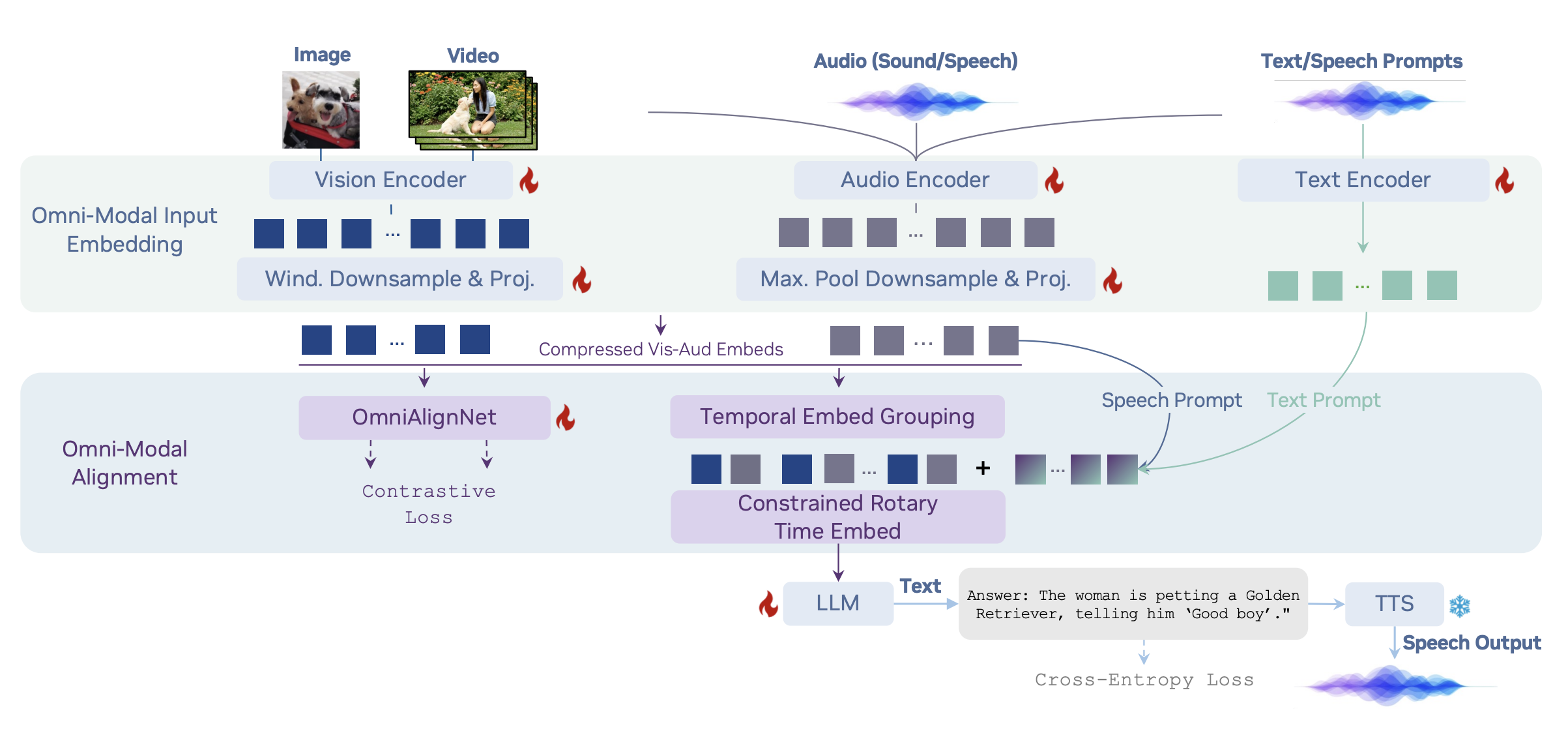
Project Lead & Corresponding Author NVIDIA Technical Report, 2025 arXiv / code OmniVinci is an omni-modal LLM for joint understanding of vision, audio, and language, while outputing text and speech. |

|
An-Chieh Cheng*^, Yandong Ji*, Zhaojing Yang*, Xueyan Zou, Jan Kautz, Erdem Bıyık, Hongxu Yin‡, Sifei Liu‡, Xiaolong Wang‡ RSS, 2025 arXiv VILA navigation model for humanoid and other legged robots with real-time deployment. |
|
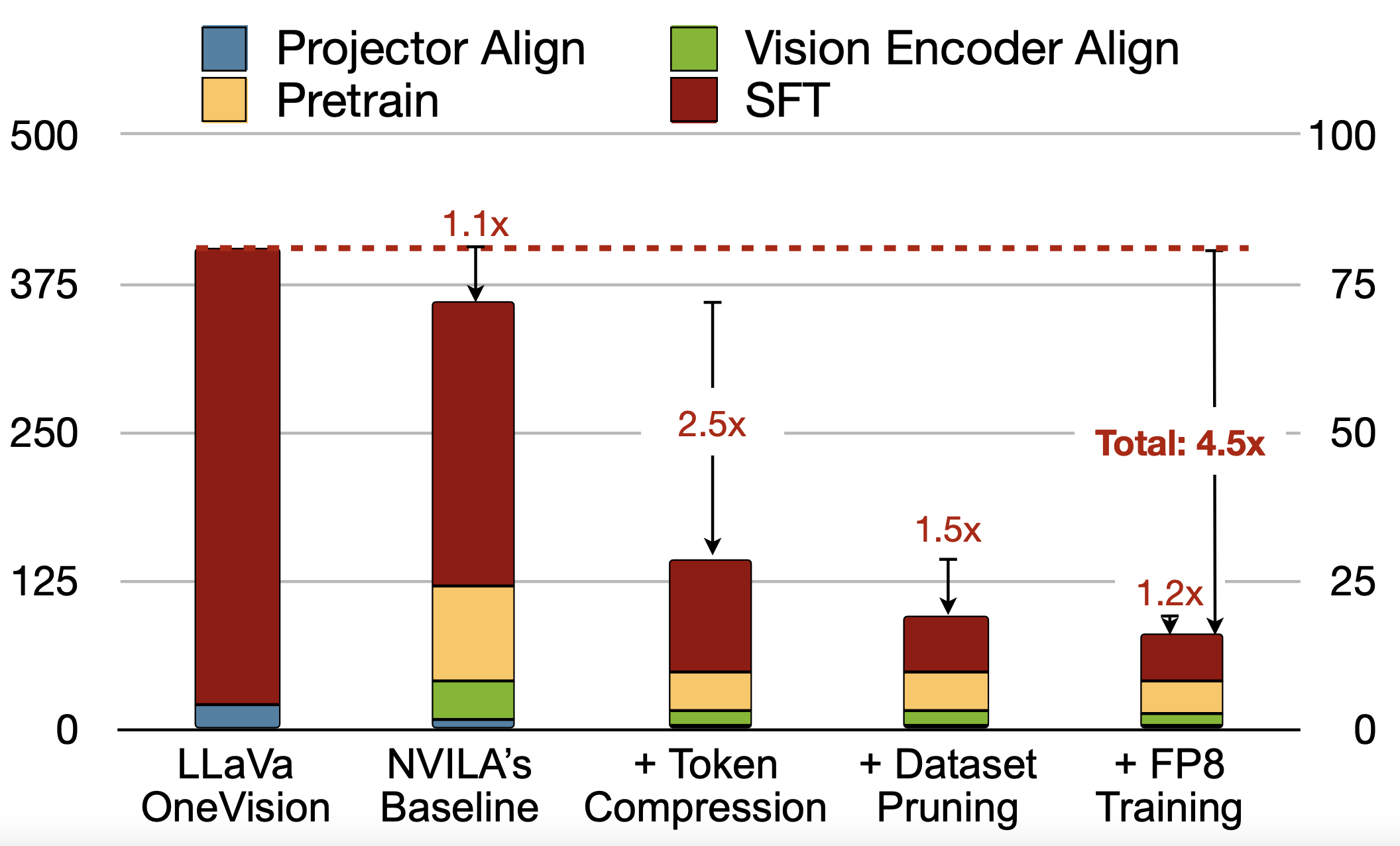
Zhijian Liu*, Ligeng Zhu*, Baifeng Shi, Zhuoyang Zhang, Yuming Lou, Shang Yang, Haocheng Xi, Shiyi Cao, Yuxian Gu, Dacheng Li, Xiuyu Li, Yunhao Fang, Yukang Chen, Cheng-Yu Hsieh, De-An Huang, An-Chieh Cheng, Vishwesh Nath, Jinyi Hu, Sifei Liu, Ranjay Krishna, Daguang Xu, Xiaolong Wang, Pavlo Molchanov, Jan Kautz, Hongxu Yin‡, Song Han‡, Yao Lu‡ CVPR, 2025 arXiv / code & checkpoints Efficient frontier VLM models with efficient training and inference. |

|
Baifeng Shi^, Boyi Li, Han Cai, Yao Lu, Sifei Liu, Marco Pavone, Jan Kautz, Song Han, Trevor Darrell, Pavlo Molchanov, Hongxu Yin CVPR, 2025 (Highlight paper) arXiv/ code & checkpoints We introduce VILA-HD, an adaptive architecture that self-focuses on area of interest depending on user prompts and cuts down on computations by >10x. |
|
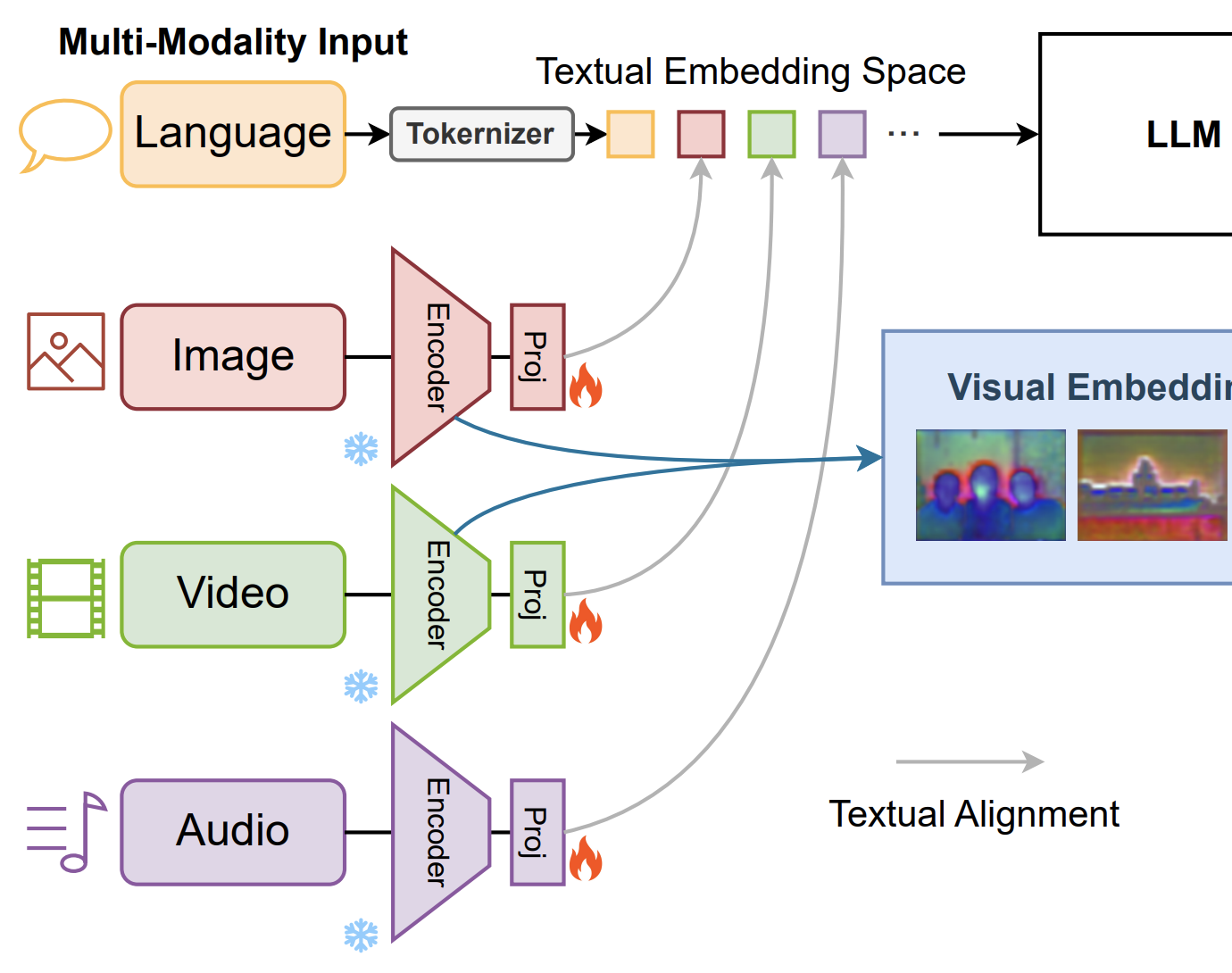
Hanrong Ye^, De-An Huang, Yao Lu, Zhiding Yu, Wei Ping, Andrew Tao, Jan Kautz, Song Han, Dan Xu, Pavlo Molchanov, Hongxu Yin preprint, 2024 arXiv We introduce X-VILA, a foundation model for cross-modality understanding, reasoning, and generation in the domains of video, image, language, and audio. X-VILA demonstrates the ability to perceive (see, hear, and read) multi-modality inputs, and generate (draw, speak, and write) multi-modality responses. |

|
Yunhao Fang^*, Ligeng Zhu*, Yao Lu, Yan Wang, Pavlo Molchanov, Jang Hyun Cho, Marco Pavone, Song Han, Hongxu Yin ICCVW, 2025 (Oral presentation) arXiv We observe three rounds of free-lunch for VLM boosting, followed by a novel specialist augmentation mechanism. |
|
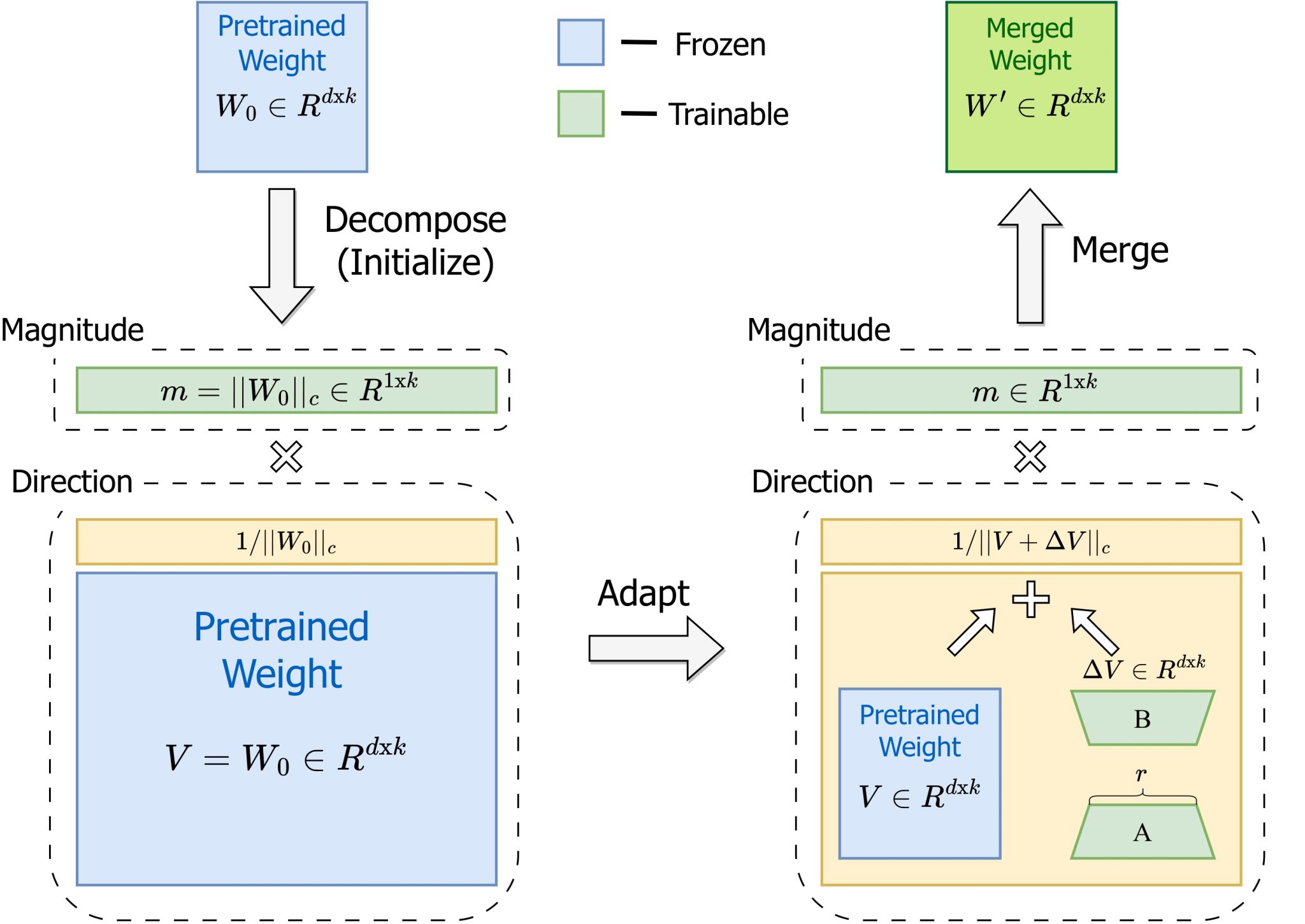
Shih-Yang Liu^, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, Kwang-Ting Cheng, Min-Hung Chen ICML, 2024 (Oral - top 1.5%) arXiv / code DoRA consistently outperforms LoRA on fine-tuning LLaMA, LLaVA, and VL-BART on various downstream tasks, such as commonsense reasoning, visual instruction tuning, and image/video-text understanding. |

|
Qiushan Guo^, Shalini d'Mello*, Hongxu Yin*, Wonmin Byeon, Ka Chun Cheung, Yizhou Yu, Ping Luo, Sifei Liu CVPR, 2024 arXiv We introduce RegionGPT that enables complex region-level captioning, reasoning, classification, and expression comprehension capabilities for the multimodal large language model. |
|
Jiaming Song, Qinsheng Zhang, Hongxu Yin, Morteza Mardani, Ming-Yu Liu, Jan Kautz, Yongxin Chen, Arash Vahdat ICML, 2023 arXiv Diffusion model for Plug-and-Play controllable generation. |
|
Divyam Madaan^, Hongxu Yin, Wonmin Byeon, Jan Kautz, Pavlo Molchanov CVPR, 2023 (Highlight - top 2.5%) arXiv / code Continual learning is now enabled for evolving model architecture upgrades. Your current model and new data are all you need to swap into a stronger architecture. |
|
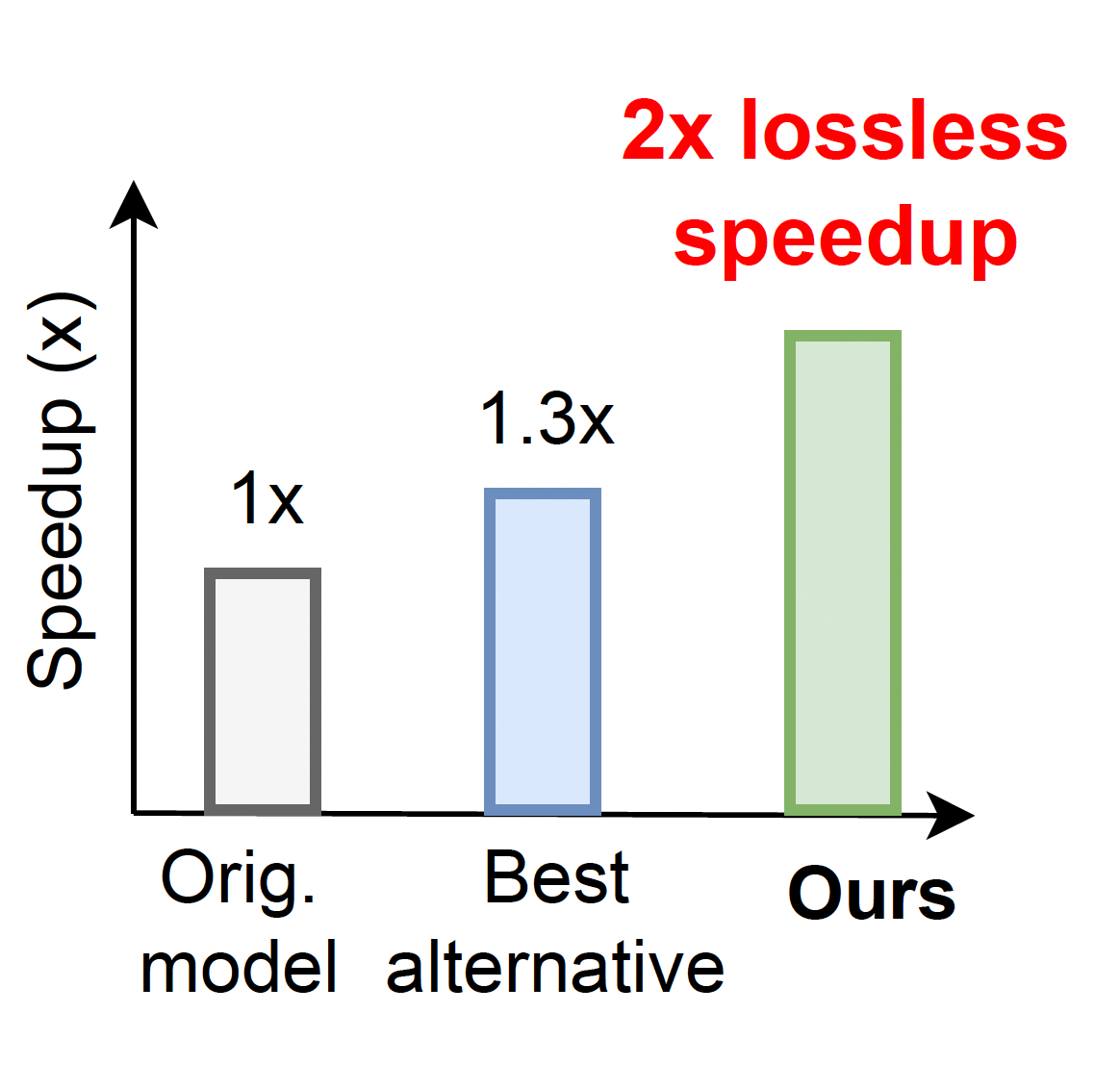
Huanrui Yang^, Hongxu Yin, Maying Shen, Pavlo Molchanov, Hai Li, Jan Kautz CVPR, 2023 arXiv / code Transformers are vastly redundant, and one-click global structural pruning offers speed up right away. Stacking same block across depth is lazy, and a new distribution rule is proposed based on embedding only. |
|
Paul Micaelli^, Arash Vahdat, Hongxu Yin, Jan Kautz, Pavlo Molchanov CVPR, 2023 arXiv / code (to come) Deep equilibrium models smooth out flickering effect in video, enabled through recurrence without temporal-aware training, yielding efficient early stopping. |

|
Xin Dong^, Hongxu Yin, Jose M. Alvarez, Jan Kautz, Pavlo Molchanov, H. T. Kung BMVC, 2022 arXiv / code (to come) We show viability to train an invert network that maps intermediate tensors back to inputs. Works smoothingly for GANs and classifiers on high resolution tasks. |
|
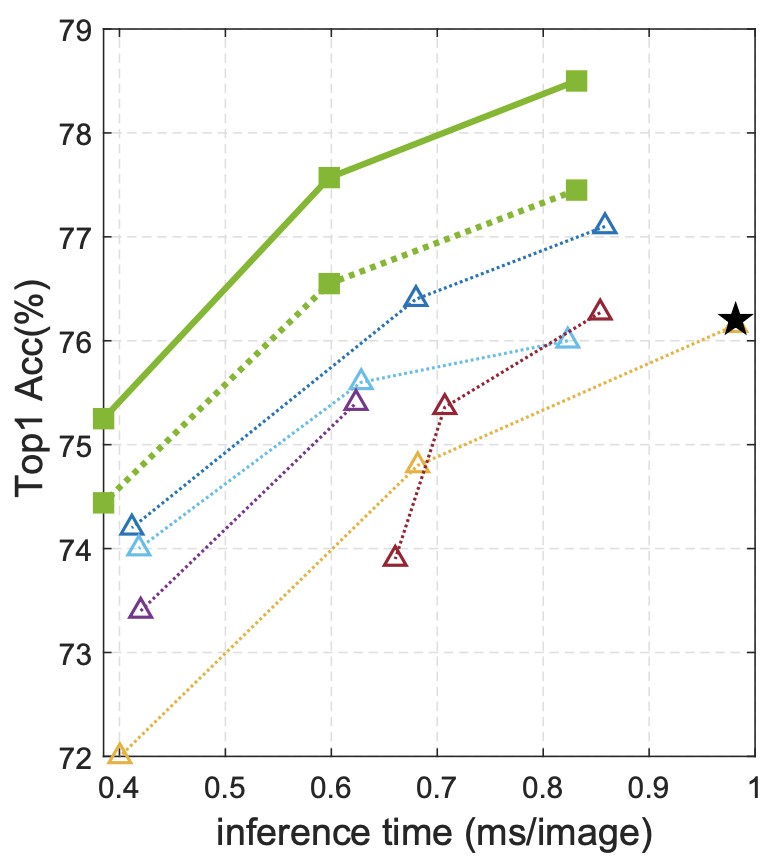
Maying Shen*, Hongxu Yin*, Pavlo Molchanov, Lei Mao, Jianna Liu, Jose M. Alvarez NeurIPS, 2022 project page / code / arXiv Sturcutral pruning is a quick knapsack problem to maximize accuracy through combining latency-guided parameter chunks. |

|
Hongxu Yin, Arash Vahdat, Jose Alvarez, Arun Mallya, Jan Kautz, Pavlo Molchanov CVPR, 2022 (Oral presentation) project page / code / arXiv We show that transformers can quickly drop redundant tokens and reserve computation on only informative ones, offering off-the-shelf cost saving. |

|
Ali Hatamizadeh*, Hongxu Yin*, Holger Roth, Wenqi Li, Jan Kautz, Daguang Xu, Pavlo Molchanov CVPR, 2022 project page / code (to come) / arXiv We show Vision Transformer gradient encode sufficient information such that private original images can be easily reconstructed via inversion. |
|
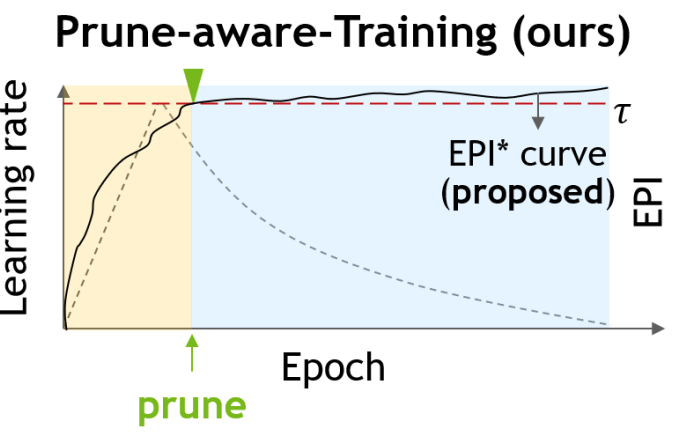
Maying Shen, Pavlo Molchanov, Hongxu Yin, Jose M. Alvarez CVPR, 2022 arXiv We push structural pruning into earlier training, cutting down on training costs. |
|
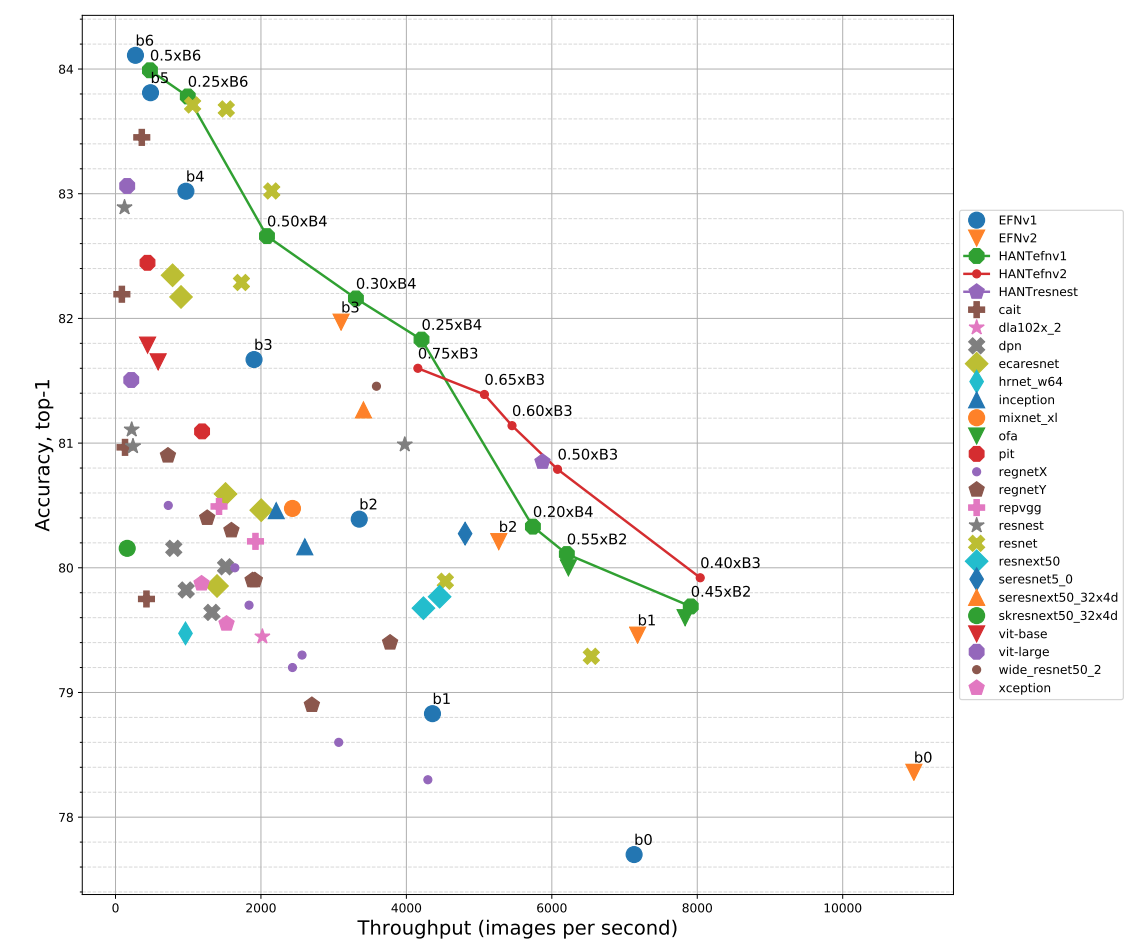
Pavlo Molchanov*, Jimmy Hall*, Hongxu Yin*, Nicolo Fusi, Jan Kautz, Arash Vahdat ECCV (to appear), 2022 arXiv We argue for a Train-Large-Swap-Faster model acceleration paradigm. Quickly adapting a large model to varying constraints in CPU-second search yields the quick finding of Pareto front. |

|
Hongxu Yin, Arun Mallya, Arash Vahdat, Jose M. Alvarez, Jan Kautz, Pavlo Molchanov CVPR, 2021 code (to come) / arXiv We show under strong inversion, gradients are in essence original data via inversion, even for large datasets, large nets, for high resolution. |

|
Yerlan Idelbayev^, Pavlo Molchanov, Maying Shen, Hongxu Yin, Miguel A Carreira-Perpinán, Jose M Alvarez CVPR, 2021 We aim at code-book oriented best scaled optimal quantization for deep nets. |

|
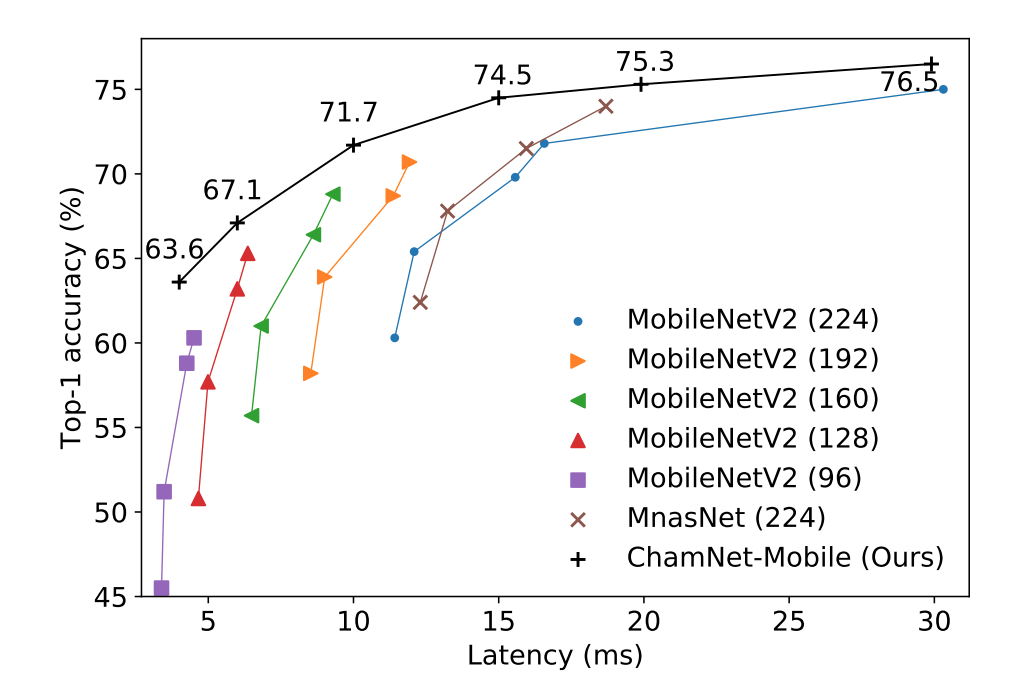
Hongxu Yin, Pavlo Molvhanov, Jose M. Alvarez, Zhizhong Li, Arun Mallya, Derek Hoiem, Niraj K. Jha, Jan Kautz CVPR, 2020 (Oral presentation) code / arXiv We show that trained deep nets are in essence datasets. One can quickly invert from net outputs to synthesize a new dataset for off-the-shelf models. See ResNet-50 dreamed objects as left. |
|
Xiaoliang Dai, Peizhao Zhang, Bichen Wu, Hongxu Yin, Fei Sun, Yanghan Wang, Marat Dukhan, Yunqing Hu, Yiming Wu, Yangqing Jia, Peter Vajda, Matt Uyttendaele, Niraj K. Jha CVPR, 2019 code / arXiv A genetic algorithm to quickly adjust the hyper architecture of a base model to target platforms (DSP, CPU, GPU) given constraints such as latency or memory. |

|
Hongxu Yin, Bilal Mukadam, Xiaoliang Dai, Niraj K. Jha IEEE Trans. Emerging Topics in Computing, 2019 arXiv Wearable medical sensors, backed by extremely efficient NNs, offers around-the-clock diabetes diagnosis. |
|
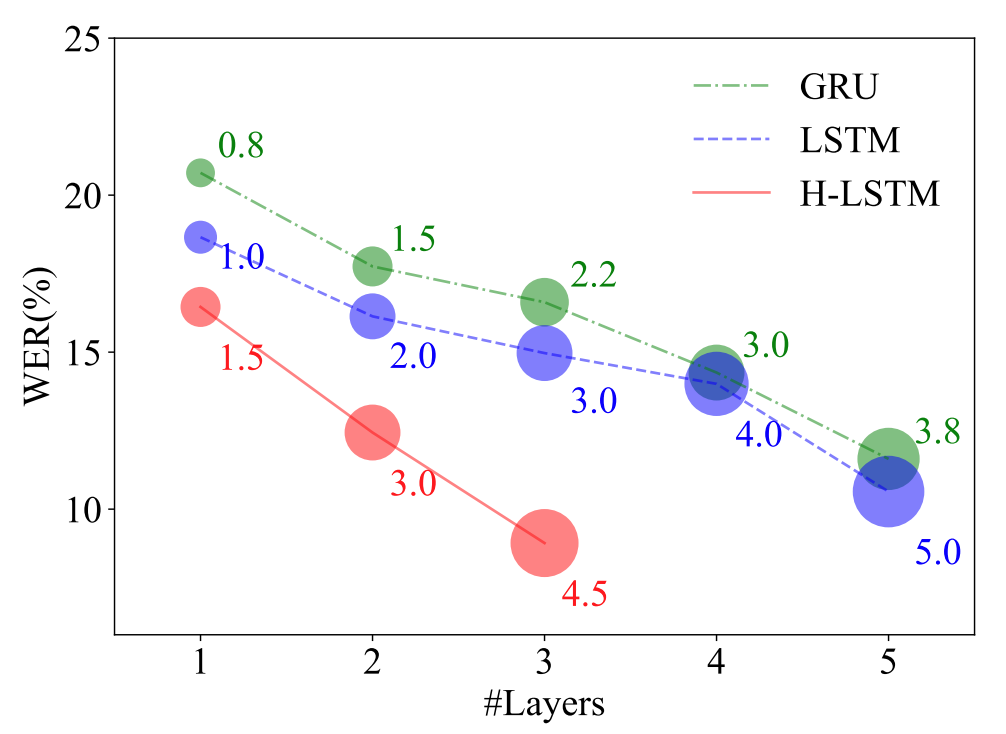
Xiaoliang Dai*, Hongxu Yin*, Niraj K Jha IEEE Trans. Computers, 2019 arXiv We show that grow-and-prune yields faster yet more accurate H-LSTM family, surpassing LSTMs and GRUs. |
|
Hongxu Yin, Guoyang Chen, Yingmin Li, Shuai Che, Weifeng Zhang, Niraj K Jha IEEE Trans. Emerging Topics in Computing, 2019 arXiv We observe high degree of non-monoticity in latency surface given shrinking model dimensions, and propose a systematic structural Grow-and-Prune way to exlpoit this for faster inference. |
|
Xiaoliang Dai, Hongxu Yin, Niraj K Jha IEEE Trans. Computers, 2019 arXiv Human brains grow before age 2 before pruning neurons for efficient synapsis afterwards. We propose grow-and-prune accordingly, and show consistent improvements over conventional pruning that always start from full models. |

|
Hongxu Yin, Ayten Ozge Akmandor, Niraj K. Jha Foundations & Trends, 2017, (Book chapter) arXiv We aim to lay out foundations for pervasive healthcare from a wearables angle. Book now available at Amazon. |

|
Hongxu Yin, Bah Hwee Gwee, Zhiping Lin, Anil Kumar, Sirajudeen Gulam Razul, Chong Meng Samson See ISCAS, 2015 (Oral presentation) arXiv An FPGA solution augmented by a novel real-time tri-core SVD design for multi-coset signal reconstruction. |
|
Partial list here. |
|
|
|
♢ Data-efficient Deep Learning, Keynote, ICLRW'23
♢ GPU-based Efficient Deep Learning and Research Fronts, Keynote, CVPRW'23 ♢ Towards Efficient and Secure Deep Learning, Invited Keynote, Design & Automation Conference (DAC'60) ♢ Towards Efficient and Secure Deep Nets, University of British Columbia ECE Department ♢ Inverting Deep Nets, Princeton University, Department of Computer Science research groups ♢ See through Gradients, Europe ML meeting ♢ Dreaming to Distill, Synced AI (机器之心) ♢ Dreaming to Distill, Facebook AR/VR ♢ Making Neural Networks Efficient, Alibaba Cloud / Platform AI group ♢ Efficient Neural Networks, Efficient Neural Networks ♢ Efficient Neural Networks, Baidu Research, ByteDance A.I. Lab US ♢ Efficient Neural Networks, Alibaba A.I. Research, Kwai Lab ♢ Applied Machine Learning: From Theory to Practice, Invited Keynote, IEEE Circuits and Systems Society (Singapore Chapter) ♢ A Health Decision Support System for Disease Diagnosis, New Jersey Tech Council |
|
|
|
(Conferences)
♢ Computer Vision and Pattern Recognition (CVPR) ♢ Conference on Neural Information Processing Systems (NeurIPS) ♢ International Conference on Machine Learning (ICML) ♢ International Conference on Learning Representations (ICLR) ♢ European Conference on Computer Vision (ECCV) ♢ International Conference on Computer Vision (ICCV) ♢ British Machine Vision Conference (BMVC) ♢ Winter Conference on Applications of Computer Vision (WACV) ♢ AAAI Conference on Artificial Intelligence (AAAI) ♢ Design Automation Conference (DAC) ♢ High-Performance Computer Architecture (HPCA) (Journals) ♢ IEEE Transactions on Pattern Analysis and Machine Intelligence ♢ IEEE Transactions on Neural Networks and Learning Systems ♢ International Journal of Computer Vision ♢ IEEE Journal of Biomedical and Health Informatics ♢ IEEE Journal of Selected Topics in Signal Processing ♢ IEEE Sensors Journal ♢ IEEE Consumer Electronics Magazine ♢ International Journal on Artificial Intelligence Tools ♢ International Journal of Systems Architecture ♢ International Journal of Healthcare Technology and Management ♢ International Journal of Electronic Imaging |
|
|
|
(NVIDIA Research Interns)
♢ Baifeng Shi, Ph.D., University of California, Berkeley ♢ Hanrong Ye, Ph.D., Hong Kong University of Science and Technology ♢ Ji Lin, Ph.D., Massachusetts Institute of Technology ♢ Zhen Dong, Ph.D., University of California, Berkeley ♢ Huanrui Yang, Ph.D., Duke University ♢ Xin Dong, Ph.D., Harvard University ♢ Divyam Madaan, Ph.D., New York University ♢ Annamarie Bair, Ph.D., Carnegie Mellon University (Princeton Senior Thesis Mentees) ♢ Joe Zhang, now Ph.D. at Stanford ♢ Hari Santhanam, now Ph.D. at University of Pennsylvania ♢ Frederick Hertan, now at SIG Trading ♢ Kyle Johnson, now at Princeton University ♢ Bilal Mukadam, now at Microsoft ♢ Chloe Song, now at Astra Inc. |
| (web template from here, with thanks) |